







vldb(international conference on very large data bases)是数据库与数据管理领域最顶级、历史最悠久的国际学术会议之一。作为探讨数据管理、可扩展数据科学、以及数据库系统最新研究成果的全球首要论坛,该会议每年都会汇聚全球顶尖的学术界研究人员、工业界从业者、系统开发者以及供应商,共同探讨数据科学领域的前沿创新与挑战。vldb 2026将在2026年8月31日-2026年9月4日在美国波士顿举办。
qa-graphrag: query-adaptive plug-and-play retrieval integration for graph-based retrieval-augmented generation
作 者:zeang sheng, ruihong sun, jiahao xu, hanmei luo, peng chen, wentao zhang, bin cui
github链接:https://github.com/pku-dair/query-adaptive-graphrag
一、 问题背景与动机
大型语言模型(llms)展现出了卓越的能力,但它们经常遭受幻觉困扰,且缺乏最新的知识。检索增强生成(rag)通过将llm与外部知识库结合,有效缓解了这些局限性。传统的基于向量的rag在处理简单查询时非常有效,但在处理需要多跳推理的复杂查询时却显得力不从心。为了解决这一问题,图检索增强生成(graph-based rag)框架应运而生,它通过构建能够捕捉全局关系并支持多跳推理的知识图谱来提升问答能力。
然而,现有的基于图的rag方法在处理简单的基于事实的查询时,由于可能会丢失详细的实体信息,其表现经常不如基于向量的框架。近期的一些双分支图rag框架试图通过同时检索局部和全局知识来解决这个问题。但对所有查询都不加区分地从两个分支进行检索,会为许多简单查询引入不必要的计算成本和冗余信息。针对这一痛点,如何让图rag框架自动识别查询特性并动态调整检索策略,成为了进一步提升系统性能与效率的核心问题。

图 1 一个典型的图rag层次化知识库结构
数据与框架层面的实证分析
为了深入揭示现有框架的性能瓶颈,我们从数据集和检索框架两个层面对基于图的rag进行了系统性的实证分析。
1. 数据集层面分析(inter- & within-dataset analysis)
我们首先利用大语言模型作为分类器,将现有问答基准数据集中的查询划分为“局部(local)”和“全局(global)”两类。其中,“局部”查询仅需要简单的事实相关知识,无需多跳或综合分析能力;而“全局”查询则需要更高层级的总结性知识,通常依赖多跳推理或全局合成能力。分析结果显示:
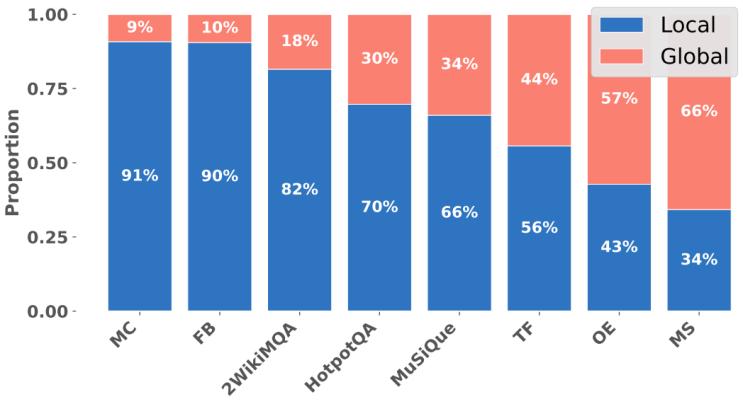
图 2 “局部”和“全局”查询在不同数据集中的比例
1)查询分布的显著差异:传统的kgqa数据集(如musique、2wikimqa、hotpotqa)主要由“局部”查询主导(例如在2wikimqa中,局部查询占比高达82%)。相比之下,专门针对图rag的基准测试 graphrag-bench 在不同任务中表现出多样化的趋势,其中多选(mc)和填空(fb)任务几乎全是局部查询,而开篇问答(oe)和多选(ms)任务中全局查询的比例显著更高。
2)查询属性的量化表征:我们提出了两个量化指标来探索两类查询的内在属性——问答语义相似度和具体度(specificity,衡量问题中命名实体或大写词元的比例)。实验表明,两类查询在语义相似度上没有实质性区别;但在具体度上,“局部”查询显著高于“全局”查询。这表明局部查询往往涉及更具体的命名实体,需要更加精准、细粒度的粒度知识来解决。
2. 框架层面分析(framework-level analysis)
接着,我们对比了不同检索框架在两类查询上的表现:
表 1 传统kgqa数据集上图rag和传统向量rag的对比
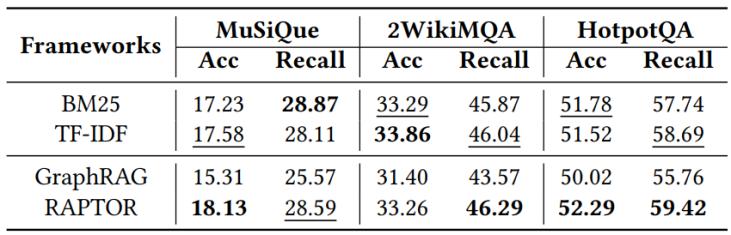
1)图rag vs. 传统向量rag:在“局部”查询主导的传统kgqa数据集上,简单的向量检索方法(如tf-idf和bm25)在部分场景下甚至可以击败复杂的图rag框架(如graphrag和raptor)。这表明在面对简单事实查询时,图rag复杂的全局检索机制不仅没有带来优势,反而可能引入了冗余噪声。
表 2 graphrag-bench上的对比结果
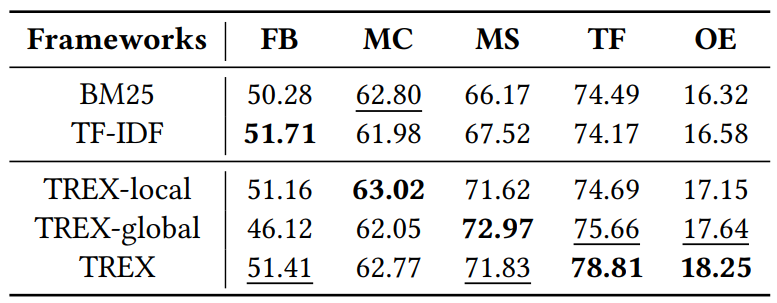
2)双分支 vs. 单分支图rag:我们将最新的双分支框架(trex)与其退化的单分支变体进行了对比。结果发现,仅保留局部检索分支的变体(trex-local)在局部查询主导的任务上超越了完整的双分支模型。同时,由于双分支模型需要同时在两个分支进行检索,其每条查询的响应时间显著增加。
3. 实证分析总结:
上述分析表明,传统向量检索(或图rag的底层原始文本块层级)更擅长处理“局部”查询,而多层级图检索则更擅长处理“全局”查询。如果一个图rag框架能够根据查询的内在属性自适应地调整其检索策略,就能同时在“局部”和“全局”查询上取得最优的性能与效率平衡。
二、qa-graphrag框架详解
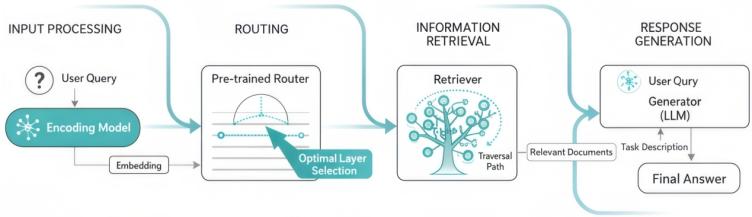
图 3. qa-graphrag的工作流程示意图
基于上述核心发现,我们提出了qa-graphrag:一个为基于图的rag框架设计的全新查询自适应即插即用检索集成模块。qa-graphrag能够兼容大多数以层级方式构建知识库并检索文本块的现有图rag框架。qa-graphrag的核心是一个灵活的路由器(router)模块,它可以根据输入查询的特征,自适应地预测并选择最佳的起始知识检索层级。该框架的部署分为两个阶段:离线预训练和在线推理。
1. 离线预训练:
为了在预测准确率和在线推理延迟之间取得最佳平衡,我们借鉴了自动机器学习中门控机制的设计直觉,采用一个轻量级的三层mlp(多层感知机)作为路由器的骨干模型 。我们实现了两种不同性能与成本权衡的路由器部署策略:
1) 跨领域预训练(generalist router/通用路由器):在包含hotpotqa、nq和triviaqa的6,000个多样化样本上进行预训练。通过将不同层级检索生成的答案准确率得分转换为 preference score 向量,并利用 gumbel-softmax 函数模拟硬选择操作进行训练。该策略使路由器具备了强大的跨领域泛化能力,且无需目标领域的标注数据。
2) 冷启动适应(specialist router/专家路由器):当目标领域有少量小样本查询(如200个样本)可用时,在通用路由器的基础上进行微调,从而定制出更适配目标数据集特征的专用路由器。
2. 在线推理:
在线推理时,qa-graphrag通过以下四个连续步骤高效处理查询:
1) 输入处理:编码模型将输入的文本查询转换为语义丰富的嵌入向量。
2) 自适应路由:预训练的mlp路由器基于查询嵌入,瞬时预测出当前查询最合适的检索起始知识层级(由于mlp计算极快,引入的时间开销微乎其微)。
3) 信息检索:检索器接收路由器的层级决策,从知识图谱对应的层级开始向下遍历并检索相关文本块,从而避免了不必要的顶层抽象汇总或底层冗余搜索。
4) 答案生成:生成器(llm)整合查询与精准检索到的上下文,生成最终的高质量答案。
三、实验结果
我们在常规的知识图谱问答(kgqa)数据集和专门针对图rag的graphrag-bench基准测试上进行了广泛的实验,并选择qwen2.5-7b-instruct作为默认的骨干llm。实验评估了将qa-graphrag集成到现有五种主流图rag框架(graphrag、raptor、lightrag、trex、hirag)中的表现。
表 3 整体性能实验对比结果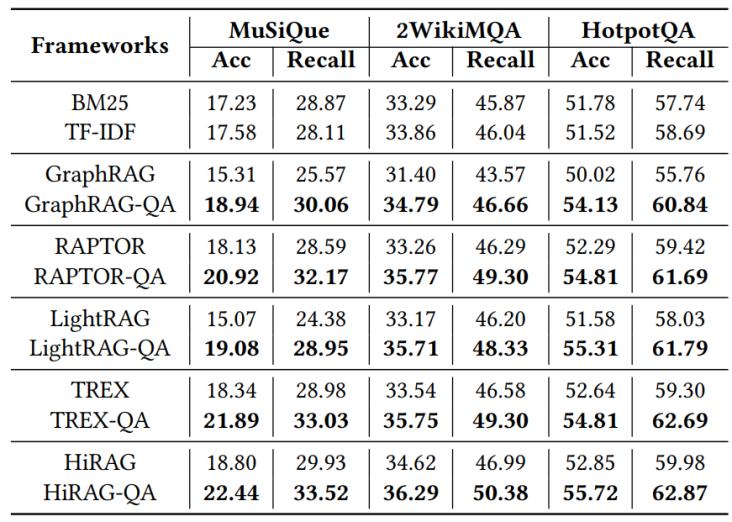
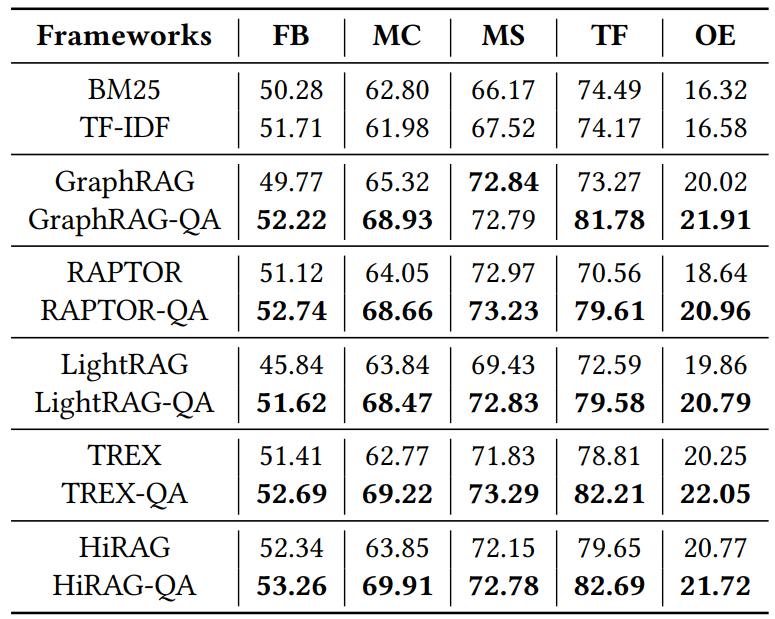
1. 整体性能显著提升:
评估结果表明,所有集成了qa-graphrag的变体(带有“-qa”后缀)在其对应的原始变体基础上均取得了显著的性能提升。例如,在musique数据集上,原始的graphrag由于检索策略固定表现欠佳,甚至被传统的bm25超越;但在集成qa-graphrag后,graphrag-qa不仅大幅超越了原始版本,还成功超越了传统检索方法。
表 4 不同路由骨干模型、算法的实验对比
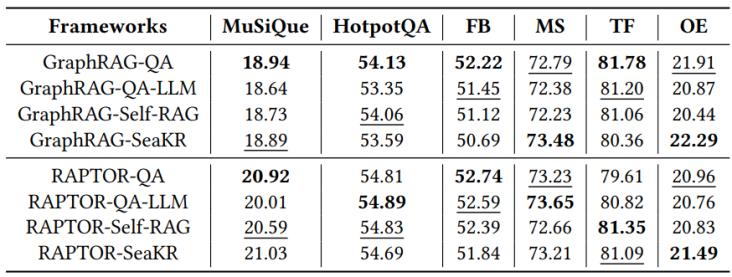
2. 路由骨干模型与基线的高效性对比:
我们将qa-graphrag(使用mlp作为路由)与使用llm(qwen2.5-3b-instruct)作为路由以及最新的自适应检索方法(self-rag、seakr)进行了对比分析。
1) 对比llm路由:实验发现,使用llm作为路由并没有带来一致的性能优势,反而引入了显著的推理延迟,导致每条查询的耗时大幅增加。mlp在保证效果的同时兼顾了极高的查询效率。
2) 对比自适应检索:相比于self-rag和seakr在某些情况下需要进行多次繁琐的检索调用,qa-graphrag对每个查询仅需执行单次检索调用即可精确定位知识层级,从而大幅降低了平均检索成本和时间开销。
表 5 不同llm基座模型的实验对比
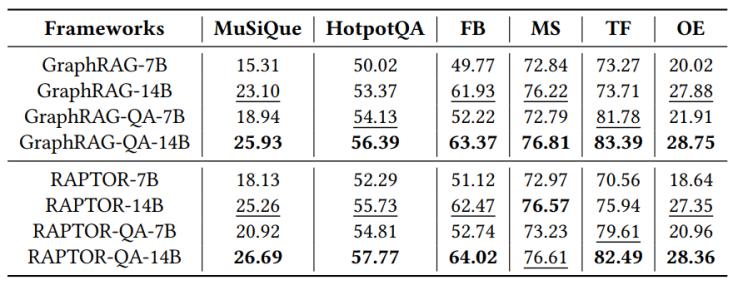
3. llm基座选择分析:
为了探究检索策略与大模型参数量之间的关系,我们将底层的llm从7b(qwen2.5-7b-instruct)替换为14b版本。正如预期,14b模型整体表现更优。然而,令人惊喜的是,装备了qa-graphrag的7b变体(如graphrag-qa-7b),在hotpotqa数据集和tf任务上的表现,甚至超越了使用更强大14b模型的原始框架(graphrag-14b)。这一“越级”表现强有力地证明了:一个聪明的自适应检索策略,完全可以在一定程度上弥补底层大模型参数规模的劣势。
表 6 不同路由器部署策略的实验对比

4. 路由器部署策略的泛化性:
我们评估了通用路由器(generalist router)与专家路由器(specialist router)的差异。结果显示,仅在外部公开数据集上训练的通用路由器,其性能稳定超越了仅在目标数据集(如hotpotqa)上训练的单领域路由器,证明了跨领域预训练能有效增强模型对通用查询特征的捕获与泛化能力。而提供少量目标数据微调的专家路由器则能在通用版的基础上进一步提供适度的精度提升,为实际部署提供了灵活的成本-性能权衡方案。
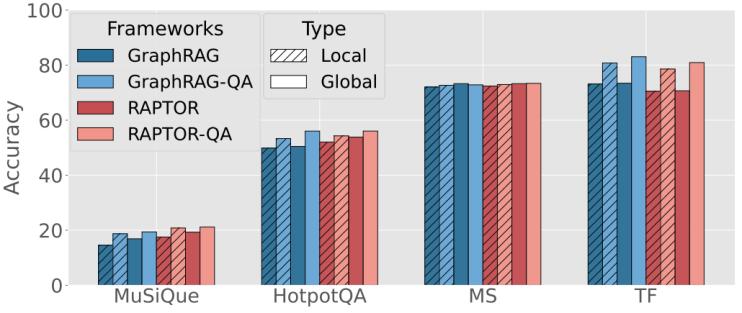
图 4 “局部”和“全局”查询各自的性能对比
5. 路由决策的细粒度分析:
我们对通用路由器在实际查询中的决策层级进行了案例分析。结果表明,路由器的输出与人类直觉高度一致。此外,我们将数据集拆分为“局部”和“全局”后分别进行评估。如图3所示,qa-graphrag不仅提升了原本就不擅长的局部查询表现,同时还在全局查询上带来了性能增益,证明了它能游刃有余地处理跨数据集的各种复杂查询类型。
四、总结
现有的基于图的rag框架在应对多样化的查询需求时,往往受限于固定的检索策略,导致“局部”查询效率低下或“全局”查询总结不足。为解决这一痛点,我们提出了qa-graphrag,这是一种即插即用、具有查询自适应能力的检索集成框架。它能够敏锐感知查询的具体度与语义特征,帮助现有的图rag框架自适应地选择最合适的检索深度。在各大基准数据集上的实验均表明,我们的方法显著增强了现有框架的问答表现,为图增强的通用检索系统设计提供了一条高能效的新路径。
参考文献
- darren edge, ha trinh, newman cheng, joshua bradley, alex chao, apurva mody, steven truitt, dasha metropolitansky, robert osazuwa ness, and jonathan larson. 2024. from local to global: a graph rag approach to query-focused summarization. arxiv preprint arxiv:2404.16130 (2024).
- parth sarthi, salman abdullah, aditi tuli, shubh khanna, anna goldie, and christopher d. manning. raptor: recursive abstractive processing for tree-organized retrieval. in the twelfth international conference on learning representations.
- yilin xiao, junnan dong, chuang zhou, su dong, qian-wen zhang, di yin, xing sun, and xiao huang. 2025. graphrag-bench: challenging domain-specific reasoning for evaluating graph retrieval-augmented generation. arxiv preprint arxiv:2506.02404 (2025).
- joyce cahoon, prerna singh, nick litombe, jonathan larson, ha trinh, yiwen zhu, andreas mueller, fotis psallidas, and carlo curino. 2025. optimizing open-domain question answering with graph-based retrieval augmented generation. in proceedings of the 1st workshop connecting academia and industry on modern integrated database and ai systems. 1-11.
北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0