







acm sigkdd conference on knowledge discovery and data mining 是数据挖掘与知识发现领域的顶级国际会议之一。kdd 2026 将于 2026 年 8 月 9 日至 13 日在韩国济州岛举办。
cofeh: llm-driven feature engineering empowered by collaborative bayesian hyperparameter optimization
作者:beicheng xu, keyao ding, wei liu, yupeng lu, bin cui
代码链接:https://github.com/pku-dair/cofeh
arxiv 链接:
问题背景与动机
一个标准的监督学习流程可以拆成两个相互关联的子问题:一是对数据进行特征工程(fe),二是对下游模型进行超参数优化(hpo)。
从 fe 的角度看,传统 automl 为了让搜索可控,通常依赖有限算子库和固定流程模板,因此难以利用领域语义,也难以构建真正自由的 fe 流水线。llm 具备语义推理和代码生成能力,为突破这一限制提供了可能。但现有 llm-based fe 方法大多仍局限于孤立子任务,尤其是特征生成。因此,论文得到第一个判断:
conclusion #1:fe 是语义密集型任务,llm 适合承担 fe 设计。
从 超参数调优的角度看。贝叶斯优化(bo)长期以来都是 hpo 中最主流的方法之一。相比之下,直接用 llm 做 hpo 往往缺乏明确的目标代理模型和不确定性估计,也难以稳定利用完整优化历史。因此,论文得到第二个判断:
conclusion #2:在 hpo 中,bo 仍然是更可靠的核心优化器。
这两个判断放在一起,就形成了本文最核心的矛盾:llm 更适合做 fe,bo 更适合做 hpo,但真正的 automl 目标并不是分别把二者做好,而是联合优化一条完整机器学习流水线。现有方法通常有两类选择。传统 automl 可以把 fe 和 hpo 放进同一个同质搜索空间中联合优化,但代价是 fe 空间被大幅限制。llm-based fe 方法则常常采用异质优化器:llm 负责 fe,bo 负责 hpo。但由于二者表示空间不同,实际流程往往退化成“先固定模型做 fe,再冻结特征做 hpo”的顺序优化。
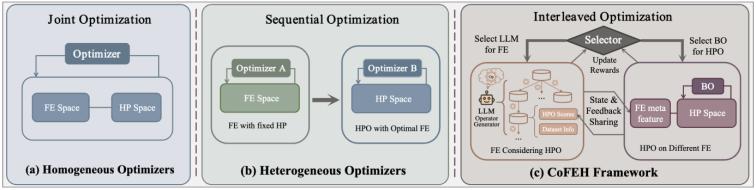
图 1. 现有方法与 cofeh 的优化流程对比
因此,论文得到第三个判断:
conclusion #3:有效的 automl 需要协同优化 llm-based fe 和 bo-based hpo。
cofeh 框架
为了解决上述问题,我们提出 cofeh,一个面向端到端 automl 的协同优化框架。cofeh 的目标不是单独优化 fe 或 hpo,而是在整个搜索过程中交替探索“特征工程流水线”和“模型超参数配置”的组合。
1. llm 如何构建自由形式的特征工程流水线
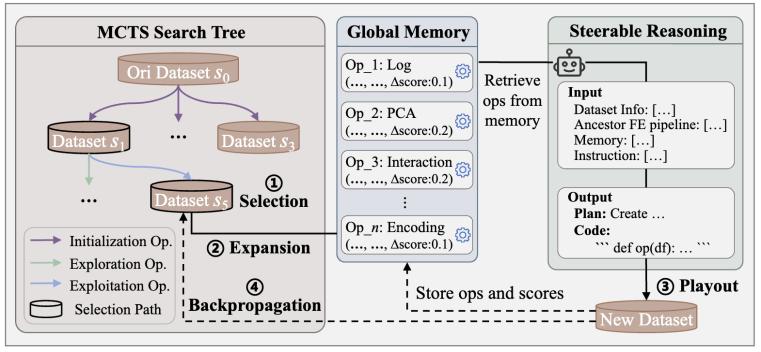
图 2. cofeh 的 llm-based fe 工作流
cofeh 将 fe 流水线构建视为一个序列决策问题。初始数据集是根节点,每执行一个特征操作,就会得到一个新的数据状态。整个 fe 搜索过程就变成了在树结构中寻找最优操作序列。具体而言,cofeh 使用 mcts 实现 tree of thought 搜索。
2. fe 与 hpo 如何协同
fe 和 hpo 本质上是相互依赖的。一个特征工程流水线的价值,需要在合适的模型超参数下才能被准确评估;反过来,超参数优化也依赖当前特征表示是否足够有效。cofeh 通过双向条件化机制打通二者。
一方面,bo-based hpo 会被 fe 状态条件化。cofeh 使用 meta-features 表征当前数据状态,并将其与超参数配置拼接起来作为 bo 代理模型的输入。这样,bo 不再只回答“哪个超参数更好”,而是回答“哪个数据状态和哪个超参数组合更好”。
另一方面,llm-based fe 也会被 hpo 结果条件化。hpo 在某个数据状态上发现更好的模型配置后,会更新该节点及其祖先节点的性能上界,引导 mcts 未来优先探索与强配置更协同的 fe 分支。
3. 动态分配 fe 与 hpo 预算
不同任务对 fe 和 hpo 的敏感性不同。有些数据集的瓶颈在特征表达,另一些数据集则更依赖模型配置。因此,cofeh 将“下一步做 fe 还是 hpo”建模为一个多臂***问题,并使用 pucb 策略动态调度。
实验结果
我们在 28 个公开数据集上评估 cofeh,其中包括 19 个分类任务和 9 个回归任务。对比方法覆盖传统自动化 fe 方法和 llm-based fe 方法,包括 openfe、mindware、octree、ellm-ft 和 lfg。主要实验结论如下:
1)只搜索 fe,使用默认下游模型超参数,cofeh 获得最优平均排名 1.82,显著优于第二名 lfg 的 3.11。
2) 在统一预算下同时优化 fe 和 hpo,cofeh 继续保持最优,平均排名达到 1.75。
3) cofeh 从 standalone fe 到 joint fe hpo 的平均改进为 7.03%,高于所有基线。
4) 在 cash 和 mlp 两类下游模型设置中,cofeh 也保持稳定优势,说明方法不依赖某个特定模型。
案例分析:从算子堆砌到语义特征工程
在 airfoil_self_noise 数据集上,cofeh 展示了与传统方法和已有 llm-based fe 方法明显不同的行为。该任务来自翼型风洞实验,目标是预测不同实验条件下的缩放自噪声。
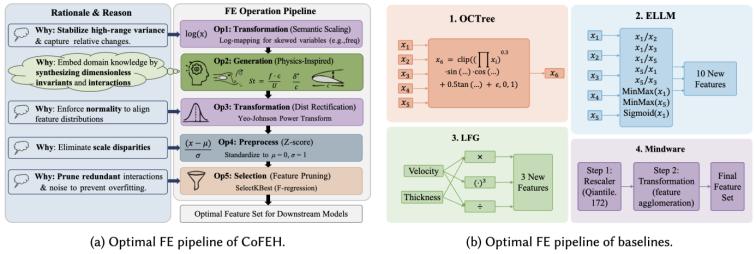
图3. cofeh方法与baselines方法搜索出的最优fe pipeline对比
cofeh 生成的流水线具有清晰的领域语义:它先对高跨度数值特征进行稳定化处理,再基于空气动力学知识构造类似 strouhal 数的特征 \(st = f \cdot c / u\),并结合攻角生成几何特征和交互项;随后继续进行分布变换、标准化和特征选择,最终得到紧凑且有效的特征表示。
我们发现,cofeh 的流水线同时覆盖了特征变换、生成、预处理和特征选择。相比之下,octree、ellm-ft、lfg 等 llm-based 方法通常主要停留在特征生成,最多再配合简单选择,难以形成完整流水线;mindware 等传统方法虽然包含预处理和变换等操作,但缺乏面向任务语义的特征构造能力。这个案例说明,cofeh能够组织一条兼具领域语义和工程完整性的fe流水线。
总结
本文提出 cofeh,将 llm-based fe 与 bo-based hpo 协同起来,实现端到端 automl 优化。cofeh 通过 tree of thought/mcts 构建自由形式 fe 流水线,通过 mutual conditioning 打通 fe 与 hpo 的信息交互,并通过 dynamic optimizer selector 自适应分配搜索预算。实验表明,cofeh 在 standalone fe 和 joint fe hpo 两种设置下均优于传统 automl 与 llm-based fe 基线,展示了 llm 语义探索能力与 bo 数值优化能力结合的潜力。
profilitable: profiling-driven tabular data processing via agentic workflows
作者: wei liu, yang gu, xi yan, zihan nan, beicheng xu, keyao ding, bin cui, wentao zhang
论文链接:https://arxiv.org/abs/2605.12376
背景与挑战
在数据科学 pipeline 中,表格处理(清洗、转换、增强、匹配)是基础但极易出错的环节。虽然大语言模型(llm)展现了自动化潜力,但在面对模糊指令和复杂任务结构时,现有方法往往因缺乏对数据的结构化理解,导致生成的代码语法正确但语义错误。例如,面对“标准化货币列”这样的指令,现有工具要么无法识别具体数值格式,要么因全量扫描所有列而导致效率低下且充满噪声。核心痛点在于:静态、规则驱动的概要信息无法自适应地探索数据,难以在精度与效率间取得平衡
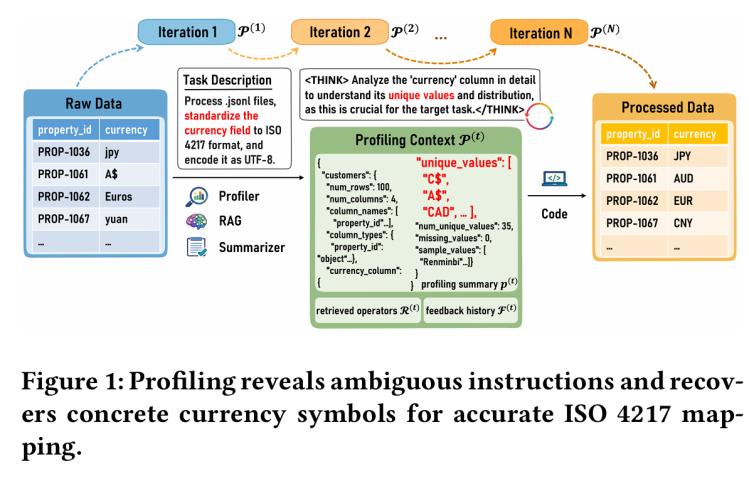
图1:概要揭示了模糊的指令暗含的信息,智能体主动采样货币列的具体取值,以实现准确的iso4217映射。
方法
针对上述问题,我们提出了 profilitable,首个以“动态概要(dynamic profiling)”为核心的自主多代理框架。它不再将概要视为被动的元数据读取,而是通过交互式探索、知识增强合成和反馈驱动优化,构建并迭代优化统一的执行上下文。
profilitable 包含三个协同机制:
- 交互式探索: profiler通过 react 循环主动探索数据,仅探索必要信息以消除歧义,避免冗余计算。
- 知识增强合成: generator利用 rag 从算子库中检索预验证的算子模板,确保生成代码的领域特异性与可靠性。
- 反馈驱动优化: evaluator-summarizer联合模块提供执行评分与诊断洞察,指导 profiler 和 generator 进行迭代修正,实现从意图到验证的连贯推理。
其架构如图2所示,形成了一个自我改进的闭环流水线。
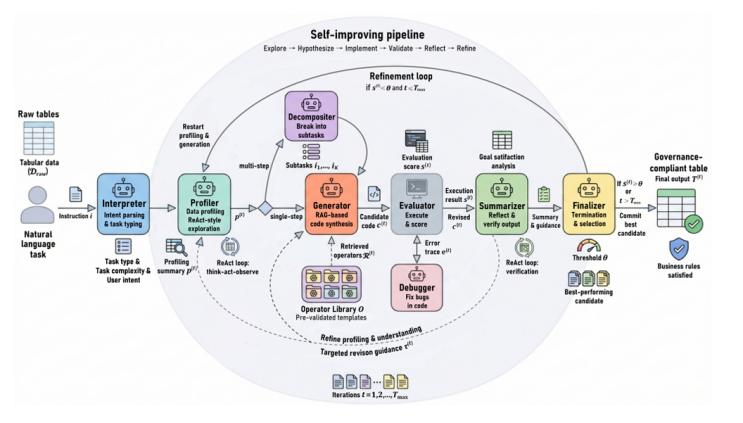
图2:profilitable 的工作流:一个以动态概要为中心的自优化、闭环管道
实验
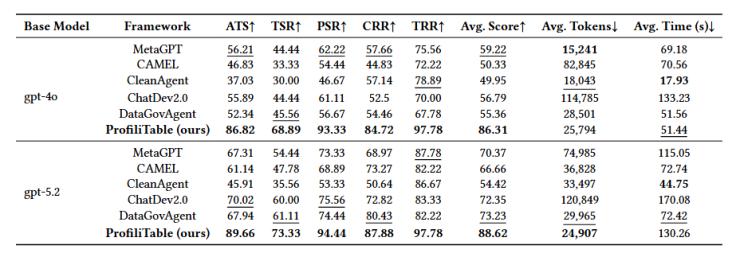
我们在涵盖 18 种表格处理任务类型的综合基准上进行了评估。实验表明,profilitable 在单步和多步任务中均取得了 sota 性能。它的可运行率(crr、trr)是最高的,确保了生产部署所需的鲁棒性。同时,它在保持高精度的同时,token 消耗处于 pareto 最优前沿,证明了框架在兼顾准确性与成本效率方面的巨大优势。
表1. 单步任务上profilitable与基线方法效果对比
总结
我们提出了 profilitable,这是一个基于动态概要的自主表格处理多智能体框架。实验表明,该方法在 gpt-4o 和 gpt-5.2 上均大幅超越基线,且是唯一在多步任务中实现 100% 任务级可运行率的方法,确保了代码部署的鲁棒性。此外,profilitable 在准确率与成本之间达到了帕累托最优,证明了动态概要能同时实现高收益与低成本。这项工作确立了一种新范式——概要驱动的智能体,即通过迭代、交互和容错机制,将表格视为动态且语义丰富的对象进行处理。
北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0