







asplos(acm international conference on architectural support for programming languages and operating systems)是计算机科学领域顶级的国际学术会议之一,专注于计算机体系结构、编程语言与操作系统等领域。作为中国计算机学会(ccf)推荐的a类会议,asplos是计算机系统领域最具影响力的会议之一,近年来论文接收率维持在15%-20%左右,每年接收论文约100-150篇。pku-dair实验室的论文《laer-moe: load-adaptive expert re-layout for efficient mixture-of-experts training》被asplos 2026录用。
laer-moe: load-adaptive expert re-layout for efficient mixture-of-experts training
作者:xinyi liu, yujie wang, fangcheng fu, xuefeng xiao, huixia li, jiashi li, bin cui
代码链接:
本工作的代码在 asplos 2026 的 artifact evaluation 中获得了三项徽章(badge):artifact available 表示作者提供的代码与材料已置于可公开访问的归档仓库并配有永久链接;artifact functional 表示 artifact 文档完整、可运行且通过评审方的验证;results reproduced 表示论文的主要实验结果已由评审委员会在作者提供的 artifact 上独立复现。
一、背景
混合专家模型(mixture-of-experts, moe)通过仅激活部分专家来处理输入token,能够在保持计算量不变的同时显著增加模型参数量,已成为大模型训练的重要架构。专家并行(expert parallelism, ep)是训练moe模型的关键技术,将不同专家分布在多个设备上。然而,在专家并行训练中,动态路由导致专家之间出现显著的负载不均衡:少数过载的专家会阻碍整体迭代,成为训练瓶颈。
目前,主流的解决思路主要分为两类:一方面,算法层面引入辅助损失(auxiliary loss)或丢弃token,但这会影响模型收敛和效果;另一方面,系统层面通过专家复制、专家重定位等方式调整专家布局,但会引入高昂的通信和迁移开销。这种"算法约束 系统重布局"的组合在实现上各有取舍,却难以在动态变化的路由分布下既优化专家布局又最小化重布局开销。因此,如何在二者之间取得平衡,是当前亟待解决的问题。
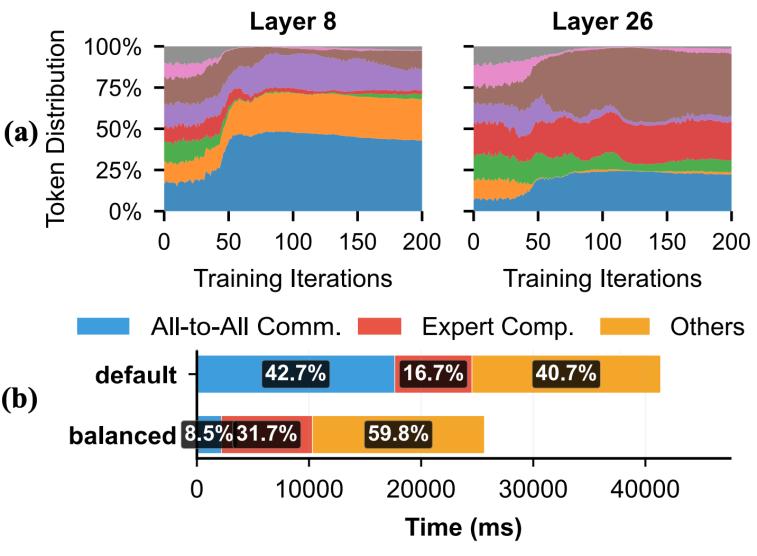
图1:专家并行中的负载不均衡与通信开销问题
二、方 法
我们提出laer-moe,一个高效的moe训练框架。其核心思想是通过并行策略与负载均衡规划器的协同设计,实现动态且高效的专家负载均衡。核心方法包括:
1. 完全分片专家并行(fully sharded expert parallel, fsep):fsep是一种新颖的并行范式,将每个专家参数按设备数量完全切分(类似于fsdp),并在前向/反向计算时通过all-to-all通信按需恢复完整的专家参数。该范式在保持与fsdp相同内存高效性的同时,允许在训练过程中灵活重布局专家参数(即决定哪个设备恢复哪个专家),从而为负载均衡提供优化空间。我们进一步通过细粒度的通信调度(预取、梯度同步延迟)有效掩盖fsep引入的通信开销。
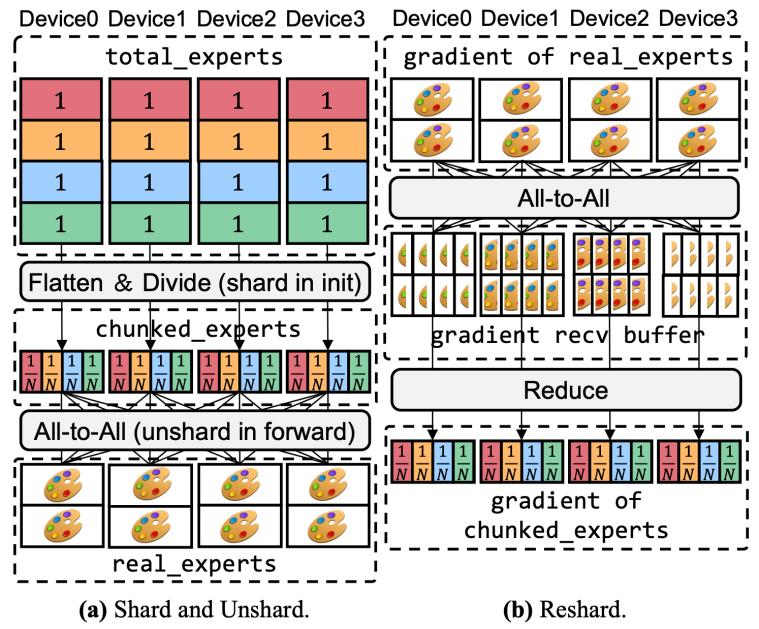
图2:fsep示意图
2. 负载均衡规划器:我们设计了智能规划器动态制定专家重布局策略与token路由方案,主要包含两个组件:token调度器采用基于贪心的轻量级路由算法,优先最小化节点间通信以快速确定token去向;专家布局调优器基于优先队列确定专家副本数量,并用贪心算法求解专家位置,以最小化计算与通信的总成本。
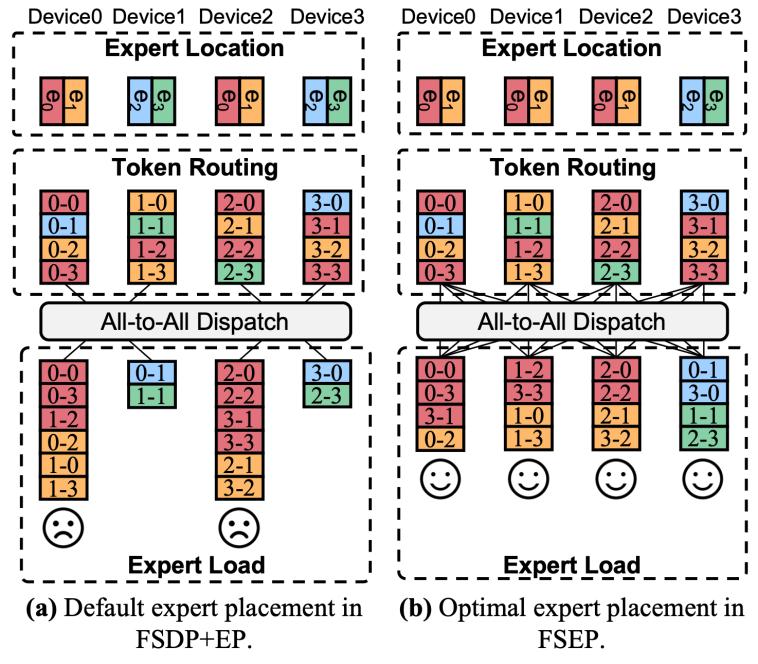
图3:使用fsep进行负载均衡的示例
3. 系统框架和整体工作流程:token调度器在训练过程中实时根据当前专家路由决定设备路由策略;专家布局调优器则基于训练过程中收集的历史路由信息,由cpu端规划器异步生成下一轮专家布局策略,实现负载均衡优化与训练执行的无缝流水线并行。
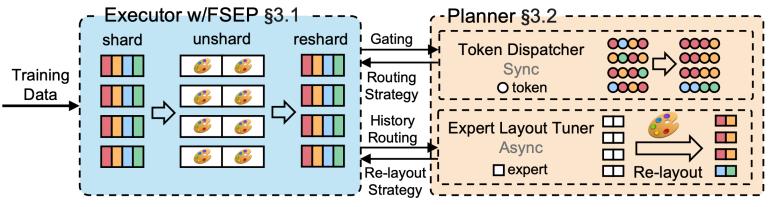
图4:系统架构图
三、实验
在32张nvidia a100集群上,我们使用mixtral-8x7b、mixtral-8x22b和qwen-8x7b模型架构,在wikitext和c4数据集上进行了广泛的实验。结果显示,相较于业界主流的megatron-lm和fsdp ep,laer-moe在吞吐量上实现了高达1.69倍的加速。实验表明,laer-moe在多种模型配置下均展现出优越的性能。
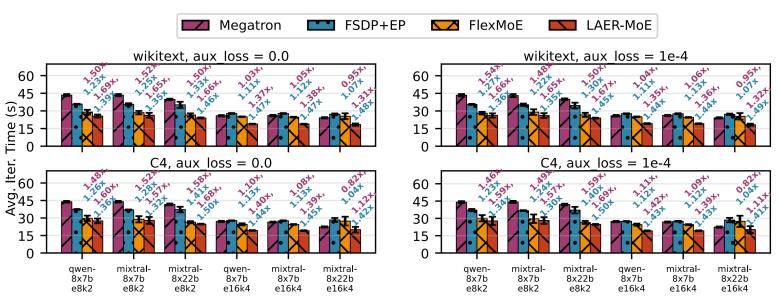
图5:端到端实验对比
四、总结
本文提出了laer-moe系统,通过完全分片专家并行(fsep)范式和智能负载均衡规划器,有效解决了moe训练中的负载不均衡问题。fsep在消除重布局开销的同时提供了极大的优化自由度,配合动态规划器,在不牺牲模型质量的前提下显著提升了训练效率。实验证明,laer-moe在多种模型配置下均展现出优越的性能,为大规模moe模型的训练提供了高效的系统支持。
北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0