







hspmd: hierarchical and heterogeneous spmd for distributed dl training
作者:haoyang li, fangcheng fu, hao ge, sheng lin, xuanyu wang, jiawen niu, yuming zhou, xupeng miao, bin cui
osdi(operating systems design and implementation)是系统领域最具影响力的会议之一,由 usenix 主办,关注操作系统、分布式系统及系统与机器学习交叉等方向。osdi长期被ccf评为a类会议,论文接收率通常在15%左右,与sosp并称为计算机系统领域的奥斯卡奖。
pku-dair实验室论文《hspmd: hierarchical and heterogeneous spmd for distributed dl training》被osdi 2026接收。
一、背景
随着gpt、gemini等大模型规模不断扩大,分布式训练已成为基础设施核心。其中,单程序多数据,即spmd(single-program multiple-data)的范式为分布式深度学习训练中的多种并行维度提供了统一抽象。用户只需写一份程序,通过张量/算子标注即可自动映射到数据并行(dp)、张量并行(tp)、流水并行(pp)等多种策略。然而,spmd依赖一个关键前提:训练负载是均匀划分的,即设备同构且数据负载一致。但在真实环境中,这一假设逐渐失效。一方面,gpu代际混用、性能差异、甚至频繁故障,使设备侧呈现显著异构性;另一方面,原始数据(如文本、图像、视频)具有天然不均匀性,导致计算负载动态变化。这些因素共同打破了spmd的对称性假设。
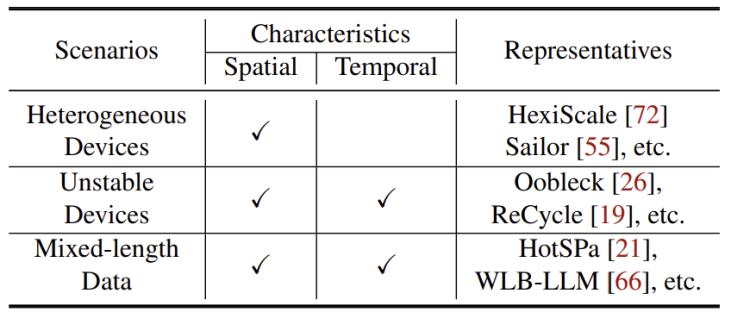
表1. 不同异构负载场景的空间/时间特征,以及代表工作
现有方法要么采用mpmd(多程序多数据)方案,但复杂且难扩展;要么在spmd基础上引入定制调度器以支持特定场景下的非对称执行,然而,这类方法通常强绑定具体场景,缺乏通用性。为此,我们提出了hspmd,其从更基础的抽象出发,在原语层扩展spmd,使其原生支持异构执行,并提出面向“空间/时间异构”的统一建模与机制设计。
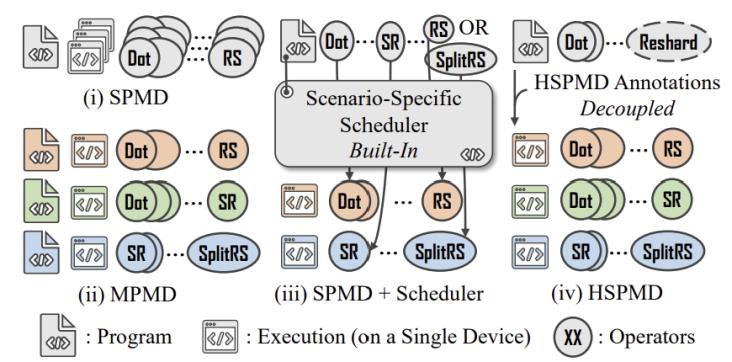
图1. 不同训练框架的范式对比
二、方法
hspmd的核心思路是在spmd的底层原语层面引入不对称性,而非像现有工作那样在调度器层面打补丁。其设计围绕三个关键创新展开:
1. 层次化、异构的切分注解:传统spmd注解只能对张量进行均匀切分。hspmd扩展了注解体系,引入dg union(设备组联合)和ds union(分布式状态联合),允许一个张量在不同设备子组内采用不同的切分方式。同时引入hdim(异构维度)和hsize(异构大小),描述跨子组的切分关系,从而在单设备编程视角下原生支持不对称并行。
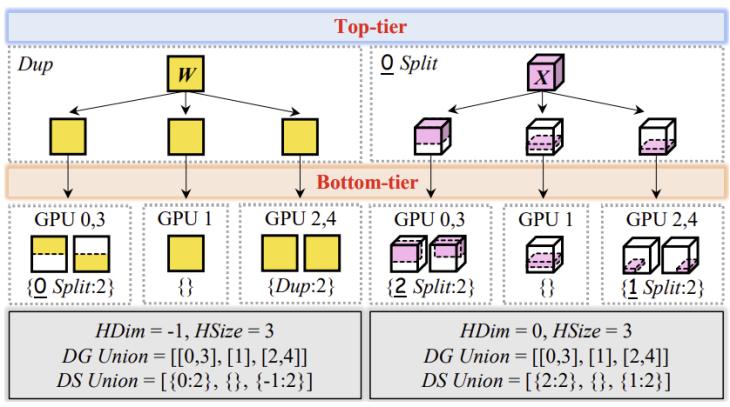
图2. 层次化、异构的切分注解
2. 层次化通信解析:根据切分注解的层次结构,hspmd将通信分为底层通信(子组内部)和顶层通信(跨子组)。底层通信尽可能复用标准spmd的集体通信原语(如all-reduce、all-gather),利用同质设备间的高带宽链路;顶层通信则处理异构链路,设计了splitar、splitag等算子,并在复杂场景下使用batched-send-receive(bsr)机制。bsr通过识别最细粒度切片、构建映射表、基于带宽优先和负载均衡的启发式调度,实现高效的非对称通信。
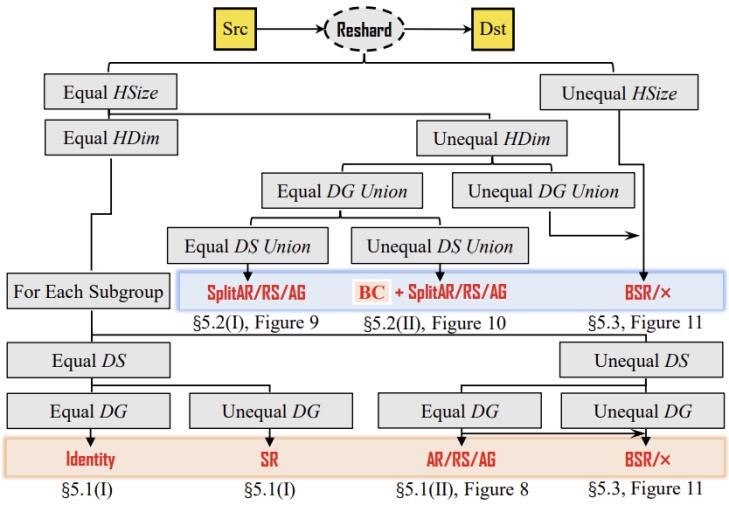
图3. 层次化通信解析
3. 图特化与图切换:针对空间异构性(负载静态不平衡),hspmd引入图特化:从单一定义图和注解计划出发,为每个设备生成专属的可执行图,设备间可执行不同逻辑。针对时间异构性(负载动态变化),hspmd引入图切换:当训练策略需重配时(如设备故障、数据分布变化),通过bsr在线重分片模型权重,无缝切换到新策略,无需重启或重新加载检查点。
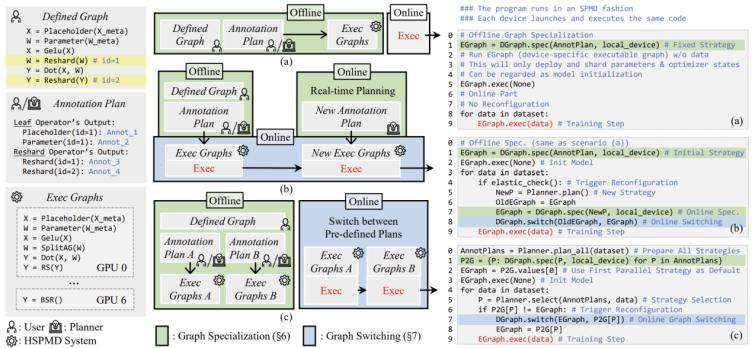
图4. hspmd工作流:图特化与图切换作为模块化构件,灵活组合以适配异构设备、不稳定设备、变长数据三类场景
三、实验
我们在16张h800和32张h20 gpu组成的异构集群上评估hspmd,采用llama系列模型(7b至32b),从三个代表性场景展开。
1. 异构设备:在混合gpu类型(h800与h20混用)的静态异构环境下,hspmd相较于标准spmd系统(deepspeed、megatron)和异构专用系统(hexiscale),训练吞吐提升显著。标准spmd因对称切分导致设备间负载失衡,而hexiscale的调度器难以支持灵活流水线(如1f1b),且仅支持粗粒度广播。hspmd通过声明式注解解耦策略与执行,配合层次化通信,实现更优的工作负载均衡与通信效率。

图5. 异构设备实验
2. 不稳定设备:我们模拟gpu故障场景,对比弹性训练性能。标准spmd只能丢弃整节点,且依赖检查点重启,恢复开销大。专用系统oobleck支持无重启重配,但策略空间受限(只能使用固定的pipeline templates)且重配通信粒度粗(只能使用broadcast)。hspmd可利用剩余所有gpu,通过张量级声明注解探索更优策略,且重配时通过fused bsr合并通信、均衡负载,显著降低切换开销。
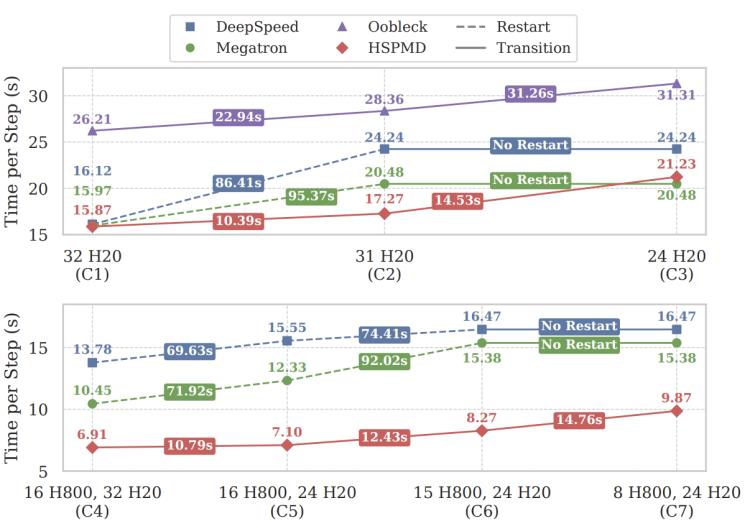
图6. 不稳定设备实验
3. 变长数据:我们训练32b模型,处理序列长度动态变化的混合数据。标准spmd固定策略在短序列为主时效率低下;hotspa虽支持策略热切换,但受限于spmd对称性,无法使用空间异构策略。hspmd预先生成多种异构策略,根据序列长度分布动态切换,在性能和灵活性上均优于基线。
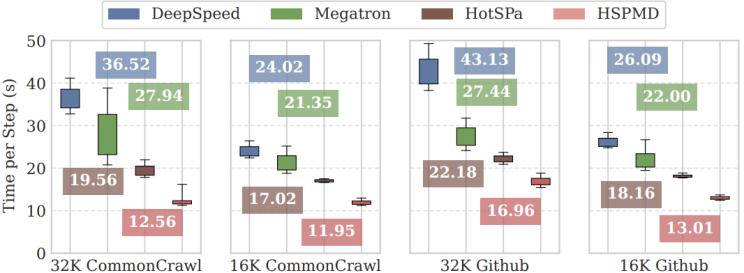
图7. 变长数据实验
四.总 结
hspmd把“spmd范式”往前推了一步:不再局限于对称的、静态的并行假设,而是正面面对设备异构、设备故障、数据分布不均等真实世界挑战。它通过在原语层面扩展注解和通信,让spmd自身具备表达和执行异构并行策略的能力,而非依赖调度器层面打补丁。
对系统设计而言,这篇工作带来两个启示:一是处理异构性应当从底层原语入手,而非在高层堆砌特设机制;二是空间异构性与时间异构性可以抽象为图特化与图切换两个正交的模块化构件,组合起来即可覆盖多种场景。这种“底层扩展 模块化抽象”的思路,为构建通用、高效的分布式训练系统提供了新的方向。
北京大学数据与智能实验室(data and intelligence research lab at peking univeristy,pku-dair实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括ccf优博、acm中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。pku-dair实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。

评论 0